
Pipelines de IA: Cómo Construí Sistemas Que Trabajan Mientras Yo Duermo
La mayoría de la gente usa IA para generar código, escribir copy o arreglarse la vida de mil formas. Le das de comer algo y te devuelve algo mejor o más estructurado. Eso está bien. Ese es el uso obvio. Pero una de las aplicaciones de mayor valor que he encontrado para la IA es construir pipelines, específicamente con Claude.
Claude está construido para esto. El modelo tiene una fuerte orientación hacia flujos de trabajo de múltiples pasos, uso de herramientas y contexto persistente. Y aunque hay otros modelos capaces ahí afuera, incluyendo algunos modelos chinos sorprendentemente buenos, voy a enfocarme en lo que he estado experimentando. Los resultados hablan por sí mismos.
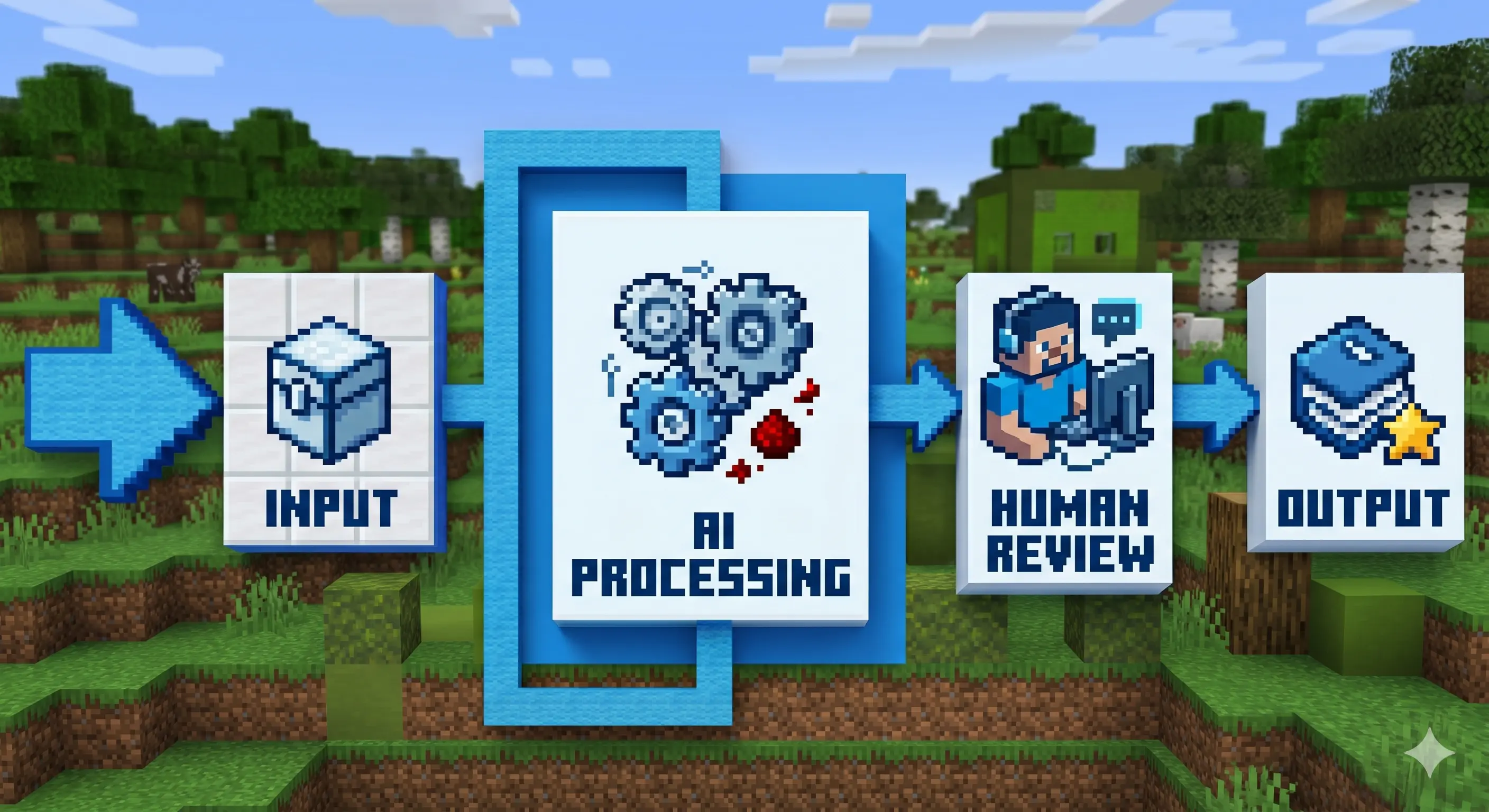
Todo pipeline de IA sigue la misma estructura: trigger, input, procesamiento con IA, revisión humana, output.
¿Qué Es un Pipeline?
Antes de mostrarte lo que construí, establezcamos qué entiendo por “pipeline”, porque la palabra se usa mucho y ayuda ser preciso.
Un pipeline es una secuencia de etapas de procesamiento donde cada etapa transforma datos de entrada y pasa el resultado a la siguiente etapa. Piensa en una refinería de petróleo: el crudo entra por un extremo y, a través de una serie de procesos químicos y físicos, obtienes gasolina, diésel y otros productos por el otro. Cada etapa tiene un trabajo específico. Ninguna podría hacer el trabajo completo por sí sola, pero juntas producen algo valioso.
En software, los pipelines están en todas partes. Los pipelines de CI/CD toman tu código, corren tests, verifican estilo, construyen artefactos y deployan, cada paso succeediendo solo si el anterior pasó. Los pipelines de datos toman datos crudos de múltiples fuentes, los limpian, transforman y cargan en un data warehouse para análisis.
Las propiedades clave de cualquier pipeline:
- Tiene etapas definidas. Cada etapa hace algo específico.
- La salida de una etapa se convierte en la entrada de la siguiente. Las etapas están encadenadas.
- Puede correr repetidamente. Misma estructura de entrada, mismo proceso, misma calidad de salida.
- Está automatizado. Una vez que lo configuras, corre sin que estés vigilando cada paso.
Ahora, ¿qué pasa cuando agregas IA a un pipeline? Ganas la habilidad de manejar etapas difusas, pasos donde la respuesta correcta no está predeterminada, donde necesitas juicio, síntesis o adaptación. Los pipelines tradicionales se rompen cuando la entrada es ambigua. Los pipelines augmentados con IA pueden manejar datos del mundo real, complejos y desordenados, y aún así producir resultados consistentes.
Las Cuatro Piezas Que Necesitas Para Construir un Pipeline de IA
Antes de construir cualquier cosa, necesitas cuatro componentes trabajando juntos:
1. Un trigger. Algo que inicia el pipeline. Puede ser un cron job corriendo dos veces al día, un archivo cayendo en una carpeta, un webhook disparándose, o tú invocándolo manualmente cuando lo necesitas.
2. Un input. Los datos que el pipeline procesa. Puede ser un CSV de un scraper, una lista de URLs, una carpeta llena de notas, o una respuesta de API. La clave es que el input tiene estructura, incluso si está desordenado, hay un patrón que puedes parsear.
3. Agentes de IA que hacen el procesamiento. Aquí es donde vive Claude (o tu modelo preferido). Cada agente tiene un rol específico: extraer datos, evaluar calidad, reescribir contenido, clasificar información, generar output. Los agentes pueden usar herramientas, leyendo archivos, navegando URLs, corriendo código, escribiendo en bases de datos.
4. Un destino de output. Donde termina el resultado procesado. Puede ser una base de datos, un PDF, un email, una página de Notion, una cola de posts de LinkedIn, o una carpeta en tu computadora.
Esa es toda la arquitectura. Todo lo que he construido sigue este patrón. Déjame mostrarte cómo se juega en la práctica.
1. Donde Empezó: CareerOps y el Pipeline de Búsqueda de Empleo
Todo comenzó cuando descubrí CareerOps, un repositorio creado por Santiago, un desarrollador que estaba intentando entrar a ingeniería de datos. Se dio cuenta de que todo el mundo estaba usando IA para leer reportes y luego ignorarlos, así que decidió combatir el fuego con fuego. El repo tiene 44,100 estrellas y ~9,300 forks en GitHub. Toma cualquier CLI de codificación con IA (Claude Code, OpenCode, o Gemini CLI) y lo convierte en un centro de comando de búsqueda de empleo. En vez de hacer tracking manual de cada aplicación, le das datos y corre un pipeline de IA que encuentra lo que necesitas.
Mi flujo de trabajo fue ligeramente modificado. No usé CareerOps para el scraping inicial de empleo. En cambio, le di un CSV generado por JobsSpy, un scraper que ya había optimizado para sacar 200-300 ofertas de empleo en múltiples regiones. Me interesaban mucho las posiciones en Estados Unidos y Canadá porque es donde mejor se paga. Junto con networking y la forma en que estuve aplicando, conseguí empleo en una empresa donde estoy muy contento. El pipeline funcionó.
Así es como funciona en la práctica: pegas una URL de empleo y CareerOps corre el pipeline completo de evaluación, asignando un score de A a F a través de 10 dimensiones ponderadas (match con CV, investigación de compensación, estrategia de nivel, prep de entrevista, y más), generando un PDF optimizado para ATS adaptado a esa oferta específica, y registrándolo en un tracker. Para diseñadores UX y vibe coders específicamente: lee la página real de descripción del trabajo vía Playwright, entiende lo que el rol realmente necesita, y adapta tu CV para ello, no keyword stuffing, sino alineación real. Santiago lo usó para evaluar 740+ ofertas, generar 100+ CVs adaptados, y conseguir un rol de Head of Applied AI.
Desde ahí, pedía la lista completa ordenada y trabajaba de la mejor a la peor, una aplicación a la vez. El sistema generaba PDFs optimizados para ATS adaptados a cada descripción de trabajo específica. Podías correr esto en batches, enviando sub-agentes para manejar múltiples aplicaciones concurrentemente. El resultado era una especie de fuente de verdad, un enfoque sistemático que convertía 300 ofertas crudas en alrededor de 30 aplicaciones enfocadas por día, corriendo enteramente sin intervención manual.
Las etapas del pipeline cuando pegas una URL de empleo:
- Input: URL de empleo pegada al CLI
- Etapa 1: Playwright abre la publicación, lee la descripción completa del trabajo
- Etapa 2: Clasifica el arquetipo del rol (LLMOps, Agentic, PM, SA, FDE, Transformation)
- Etapa 3: Evalúa a través de 10 dimensiones ponderadas: match con CV, gaps, investigación de compensación, historias STAR, prep de entrevista
- Etapa 4: Score de A a F, output de un reporte de evaluación escrito
- Etapa 5: Genera PDF optimizado para ATS adaptado a esa descripción de trabajo específica
- Etapa 6: Registra en tracker (archivo TSV, tu fuente de verdad)
- Output: Reporte de evaluación + PDF + entrada en tracker
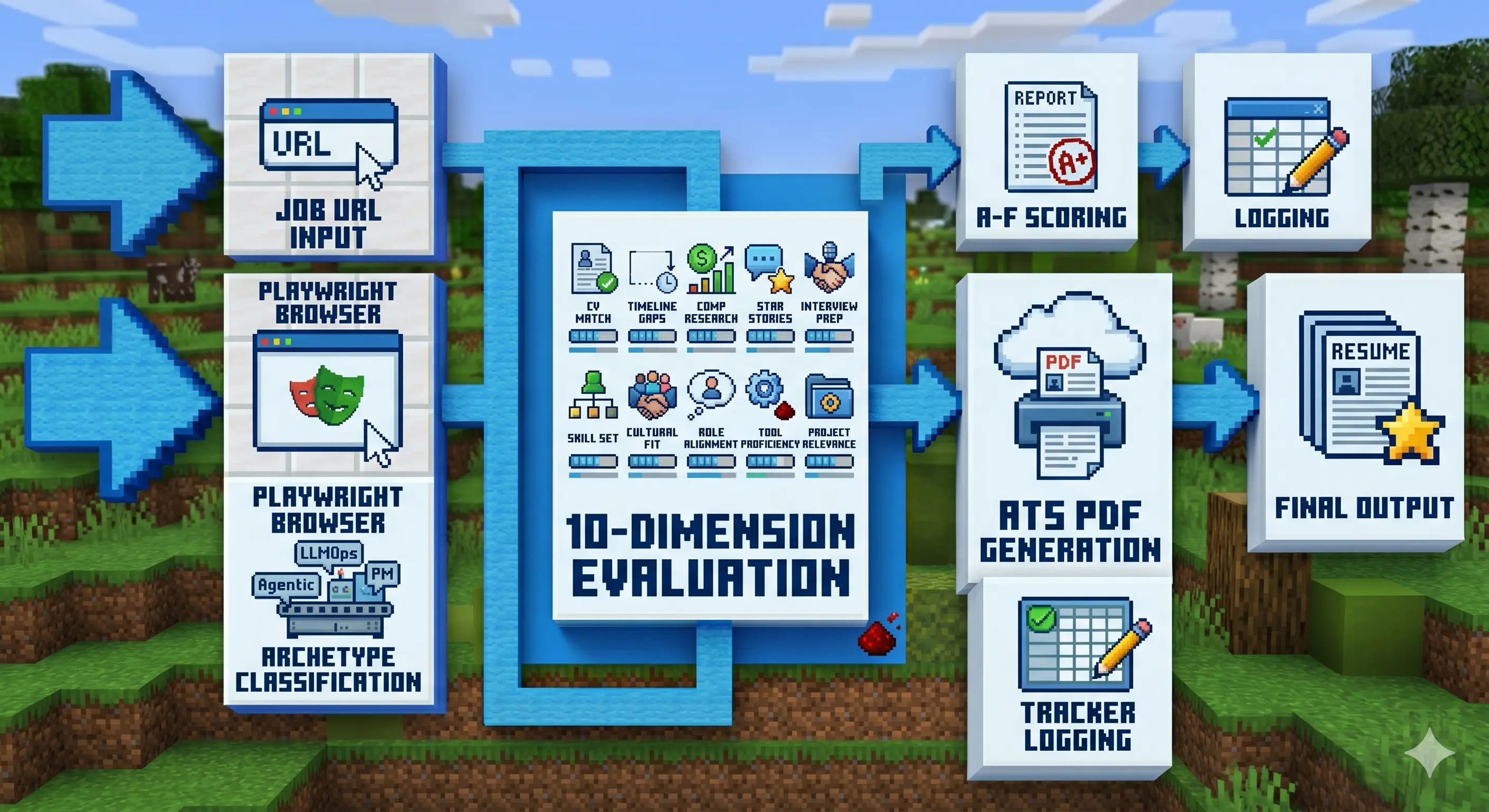
CareerOps convierte una URL de empleo en una evaluación completa, scored, y con PDF adaptado, lista para aplicar.
[!warning] CareerOps consume muchos tokens. Correr el pipeline completo en una sola URL de empleo, evalúa + generación de PDF + registro en tracker, consume una porción significativa de una sesión. Con mi suscripción de $100/mes, una sesión quemó aproximadamente 1 de mis 5 sesiones diarias. Para un batch de 10 URLs corriendo en paralelo vía sub-agentes, el consumo de tokens sube rápido. No correría esto con un plan de $20/mes. El ROI es real, pero también lo es el consumo. Empieza con una sola URL y observa tu contador.
[!important] Sobre la elección de modelo: No he usado modelos chinos para este pipeline específicamente, pero recomendaría probarlos en OpenCode. Desde hoy (5/11/2026), DeepSeek 4 Flash es gratis ahí. Para un pipeline hambriento de tokens como CareerOps, un modelo capaz y gratis cambia las matemáticas completamente.
[!info] Las posiciones con mejor score eran típicamente de empresas tier-one con restricciones de ubicación (solo Estados Unidos o Canadá), lo que hacía difícil aplicar directamente. El pipeline me ayudaba a identificarlas de entrada en vez de perder tiempo en aplicaciones rechazadas.
2. CareerOps Por Dentro: Skills Hasta el Fondo
CareerOps es impresionante, pero más simple de lo que parece. Es fundamentalmente una colección de 14 skill modes: cosas como /career-ops (pipeline completo), /career-ops-evaluate (evaluación de un solo rol), /career-ops-scan (scanner de portales para 45+ empresas), /career-ops-pdf (generación de PDF), /career-ops-batch (evaluación paralela con sub-agentes), y más. Cada modo maneja un subproceso específico. Juntos cubren el flujo completo de búsqueda de empleo.
Terminé haciéndole un fork para construir una versión enfocada en networking. Mi objetivo era alcanzar tomadores de decisiones y leads de contratación directamente, ofrecer mis servicios, y construir relaciones genuinas en la industria. Porque al final del día, networking se trata de hacer amigos en tu campo, no solo de hacer dinero.
3. El Pipeline de Contenido: De X al Carrusel de LinkedIn
Después del éxito en la búsqueda de empleo, decidí construir más pipelines. Si me sigues en LinkedIn, verás un tema recurrente: contenido sobre IA. Ese contenido no se escribe solo. Es el producto de un pipeline que construí para encontrar la mejor información y convertirla en posts.
El problema con la curación de contenido con IA naive es AI slop. Pregúntale a una IA por “las últimas noticias de IA” y te traerá resultados de Google que tienen un mes, presentados como frescos. El modelo no sabe que los resultados de Google están desactualizados; confía en el output de búsqueda. Para arreglar esto, le di a mi sistema mi lista completa de cuentas seguidas en X (alrededor de 200). El pipeline verifica esas cuentas buscando shares relevantes, especialmente anuncios de repos. Cuando encuentra algo interesante, visita el repos directamente y hace cross-reference de los claims antes de incluirlos.
Todo el contenido validado fluye hacia una base de Airtable que mantengo con URLs fuente y una logline por cada ítem. Reviso la cola y etiqueto cada entrada: aprobado, irrelevante (para que el sistema aprenda qué busco), no aprobado, o “muy viejo.” Los ítems aprobados reciben un tratamiento de copy más extenso de Claude. Siempre agrego mi propia voz. El copy de IA es bueno, pero necesita sazón. Ese es mi trabajo en el pipeline.
Una vez que todo está aprobado, un script de Python genera un PDF por post, lo sube a Airtable, y lo tengo listo para postear como carrusel en LinkedIn. Lo hice por una semana para probar. Fue efectivo. No hago auto-post. Pego manualmente en LinkedIn para mantener control sobre tiempo y ediciones finales.
Las etapas del pipeline, desglosadas:
- Trigger: Dos veces al día, o invocado manualmente
- Input: Lista de 200 cuentas de X que sigo
- Etapa 1: Trae los últimos posts de esas cuentas
- Etapa 2: Filtra por contenido relevante de IA/tech (shares de repos, artículos, herramientas)
- Etapa 3: Por cada candidato, visita la URL compartida y hace cross-reference de los claims
- Etapa 4: Escribe logline y guarda en Airtable con status de aprobación
- Etapa 5: Mi revisión manual (tag de aprobar/rechazar)
- Etapa 6: Claude genera copy extendido para los ítems aprobados
- Etapa 7: Agrego mi voz personal y ediciones finales
- Etapa 8: Script de Python genera PDF, sube a Airtable
- Output: PDF carrusel listo para subir a LinkedIn

El pipeline de contenido convierte 200 cuentas de X en una cola estructurada de posts aprobados listos para publicar.
4. Mi Pipeline de Inbox de Obsidian
Luego fui más allá y construí un pipeline para mi base de conocimiento de Obsidian.
Uso Obsidian para capturar todo lo que aprendo: notas de reuniones, clippings de artículos, cosas que estoy explorando. A pesar de tener un sistema de organización decente, igual acumula caos, archivos se acumulan en el inbox, las notas se desvían de su hogar intended, las conexiones entre ideas se desvanecen. El pipeline resuelve esto.
Usa una serie de skills y un agente dedicado que entiende cómo quiero que esté estructurado mi vault. Aquí está la configuración: tengo una carpeta Inbox donde cae todo durante la semana, clippings vía el web clipper de Obsidian, notas de reuniones, fragmentos de aprendizaje, y notas que aún no han encontrado un hogar. Una vez al día o los viernes, invoco el pipeline.
El agente lee todo en el Inbox, luego decide para cada ítem:
- ¿A qué carpeta pertenece?
- ¿Necesita una actualización de frontmatter YAML?
- ¿Debería enlazarse a notas existentes vía WikiLinks?
- ¿Necesita ser dividida, fusionada, o reescrita para claridad?
El resultado es un vault que se mantiene organizado sin que yo haga el sorting manual. Estoy testeando este flujo con OpenCode ahora mismo, y maneja la tarea excepcionalmente bien. El agente conoce mis convenciones de carpetas, entiende mi estilo de tagging, y tiene suficiente contexto para tomar decisiones de colocación sensibles.
Las etapas del pipeline, desglosadas:
- Trigger: Diario o semanal, invocado manualmente
- Input: Todo lo que está en la carpeta Inbox de Obsidian
- Etapa 1: Claude lee cada archivo, entiende su contenido
- Etapa 2: Por cada archivo, decide carpeta destino, actualiza frontmatter, crea WikiLinks a notas relacionadas
- Etapa 3: Mueve archivos a sus ubicaciones correctas, limpia el Inbox
- Output: Vault organizado sin notas huérfanas
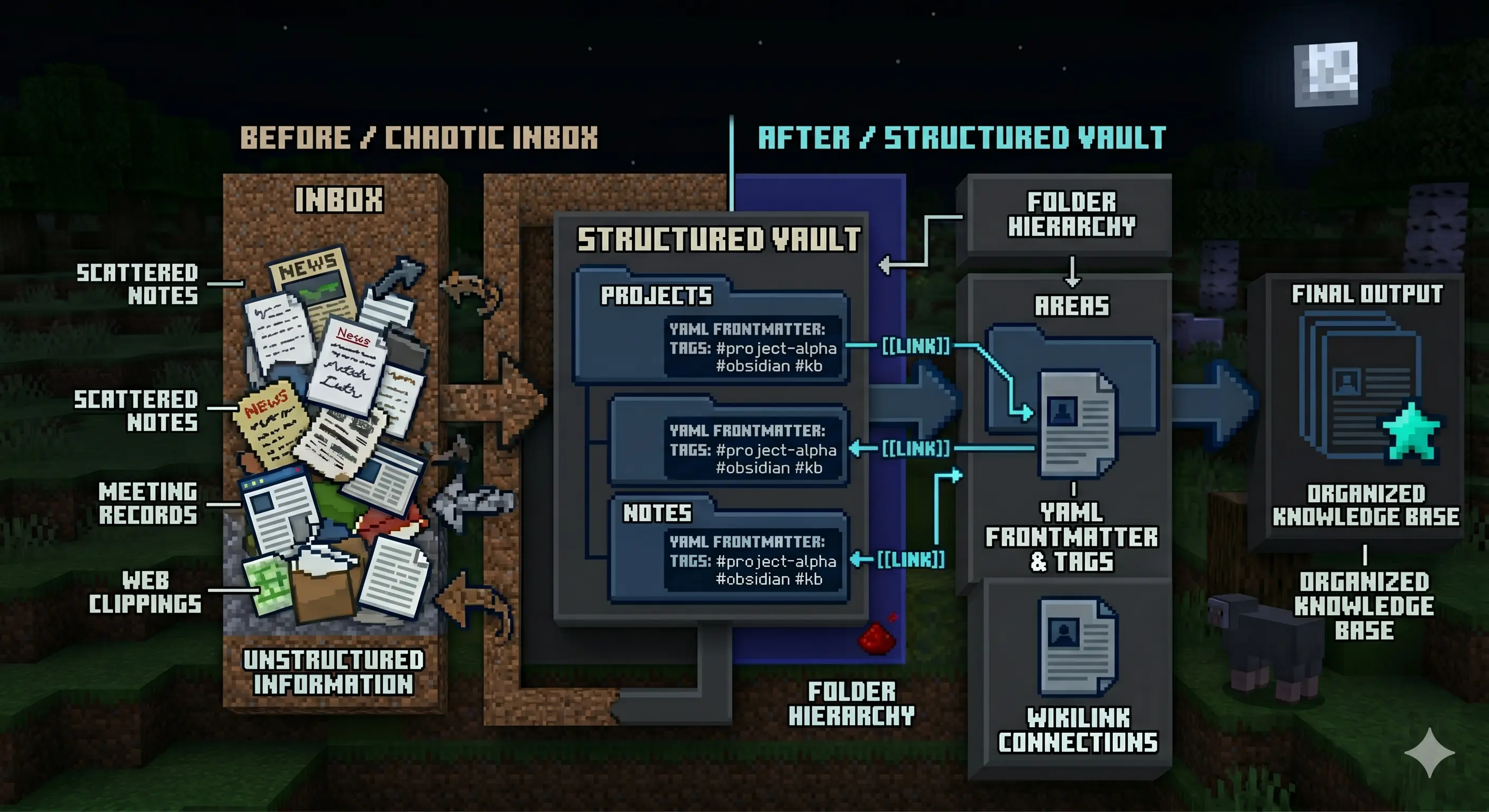
El pipeline de Obsidian transforma un Inbox caótico en un vault bien organizado con frontmatter adecuado y enlaces cruzados.
5. El Patrón Común En Todos Los Pipelines
Si miras los tres pipelines, búsqueda de empleo, curación de contenido y gestión de conocimiento, comparten la misma estructura:
- Algo dispara el pipeline (cron, webhook, invocación manual)
- Los datos entran (CSV, feed de X, carpeta Inbox)
- La IA procesa cada ítem (evalúa, scorea, reescribe, categoriza)
- El humano revisa los outputs (la llamada de juicio que la IA no puede hacer confiablemente)
- El output final se genera y entrega (PDF, post, archivos organizados)
Cada pipeline tiene un humano en el loop en la etapa de revisión. Esto es intencional. La IA maneja el trabajo mecánico, sorting, scoring, reescribir, estructurar. Tú manejas el juicio creativo y estratégico, qué merece ser posteado, qué empleo vale realmente la pena aplicar, si una nota pertenece a Projects o Areas.
[!important] La insight clave: los pipelines funcionan mejor en procesos que son estables y repetibles. Si tu flujo cambia cada semana, un pipeline costará más mantener de lo que ahorra. Encuentra el invariante primero.
6. Encontrando Tus Propios Pipelines
¿Dónde encuentras oportunidades de pipeline en tu propio trabajo? Busca cualquier cosa que siga este patrón:
- Una tarea recurrente con un formato de input definido que produce un output definido
- Pasos que son consistentes semana tras semana incluso si los datos específicos cambian
- Trabajo mecánico que toma más tiempo del que debería: sorting, clasificando, resumiendo, redactando
- Un problema de volumen: demasiados datos para procesar manualmente (cientos de ofertas de empleo, decenas de notas, miles de artículos fuente)
Algunos candidatos obvios:
- Marketing: ideación de contenido, redacción, edición, programación
- Desarrollo: spec, código, review, deploy
- Investigación: recolección, validación, análisis, síntesis
- Gestión de conocimiento: captura, categorización, enlazado, recuperación
La pregunta que debes hacerte: ¿qué proceso corro repetidamente que consume tiempo que podría gastar en trabajo de mayor valor? Ese es tu pipeline.
7. La Advertencia: La IA Todavía Alucina
Una regla no negociable: tienes que revisar todo lo que la IA produce. El pipeline maneja el trabajo pesado, filtrar, rankear, estructurar, pero la llamada final es tuya. La IA es excepcional encontrando patrones que podrías haber pasado por alto, conectando información a través de cientos de puntos de datos, y flagged things that deserve a second look. Pero también te dirá algo incorrecto con la misma confianza que usa para los hechos.
El ejemplo más concreto: el pipeline una vez intentó enviar mi aplicación al mismo trabajo dos veces el mismo día. Lo atrapé antes de que saliera, pero fue un buen recordatorio de que la IA optimizará para el objetivo declarado (aplicar a todo lo posible) sin conciencia de restricciones prácticas como “no aplicar dos veces al mismo rol.” Revisar no es una red de seguridad. Es una etapa requerida en cada pipeline.
¿Qué Sigue?
Los pipelines de IA no son magia. Son solo pensamiento de sistemas aplicado a flujos de trabajo con IA. El ROI compuesto cuando encuentras un proceso que es lo suficientemente estable para automatizar pero lo suficientemente complejo para que la ejecución manual queme tiempo que podrías gastar en trabajo de mayor valor.
Estoy enseñando a product designers, UX designers y roles similares a construir estos pipelines desde cero y a hacer vibe coding desde cero. Si necesitas guía práctica o mentoría sobre cualquiera de esto, contáctame en LinkedIn.
Pero si lo que buscas es un formato más estructurado, tengo un workshop intensivo donde enseño a configurar estos pipelines desde cero: las herramientas, los prompts, la arquitectura de skills, y los errores comunes que te vas a encontrar. Puedes ver los detalles y registrarte en xperience.ec/capacitacion/prototipado-ia.
El futuro pertenece a personas que construyen sistemas, no a personas que corren en una treadmill.